取得和导入对话补全预设
“破限”有时也是指对话补全预设
大多数提供 LLM 的服务商为了安全起见,会在训练模型时让它们回避某些话题,或是过滤包含这些内容的输出。 但很多时候它们往往矫枉过正了。
有的时候,一个设计良好的对话补全预设可以缓解这些防御措施在聊天过程中带来的不便。 出于历史原因,有些人会把包含这部分内容的对话补全预设叫做“破限”。
但本文档中依然跟随酒馆官方的称呼,称它们为“对话补全预设”。
没有一个模型能适应所有预设,也没有一种预设能够包打天下
因为不同的 LLM 能够接受的输入类型,系统提示格式,以及审查程度都互不相同,因此并不存在某种能够通吃所有模型的对话补全预设。
部分角色卡对特定预设的相性也许会更佳,你也许会在聊上一阵子之后,逐渐习惯起这个预设的文风和效果。
导入对话补全预设
你下载到的对话补全预设应该是一个 JSON 格式的文件。
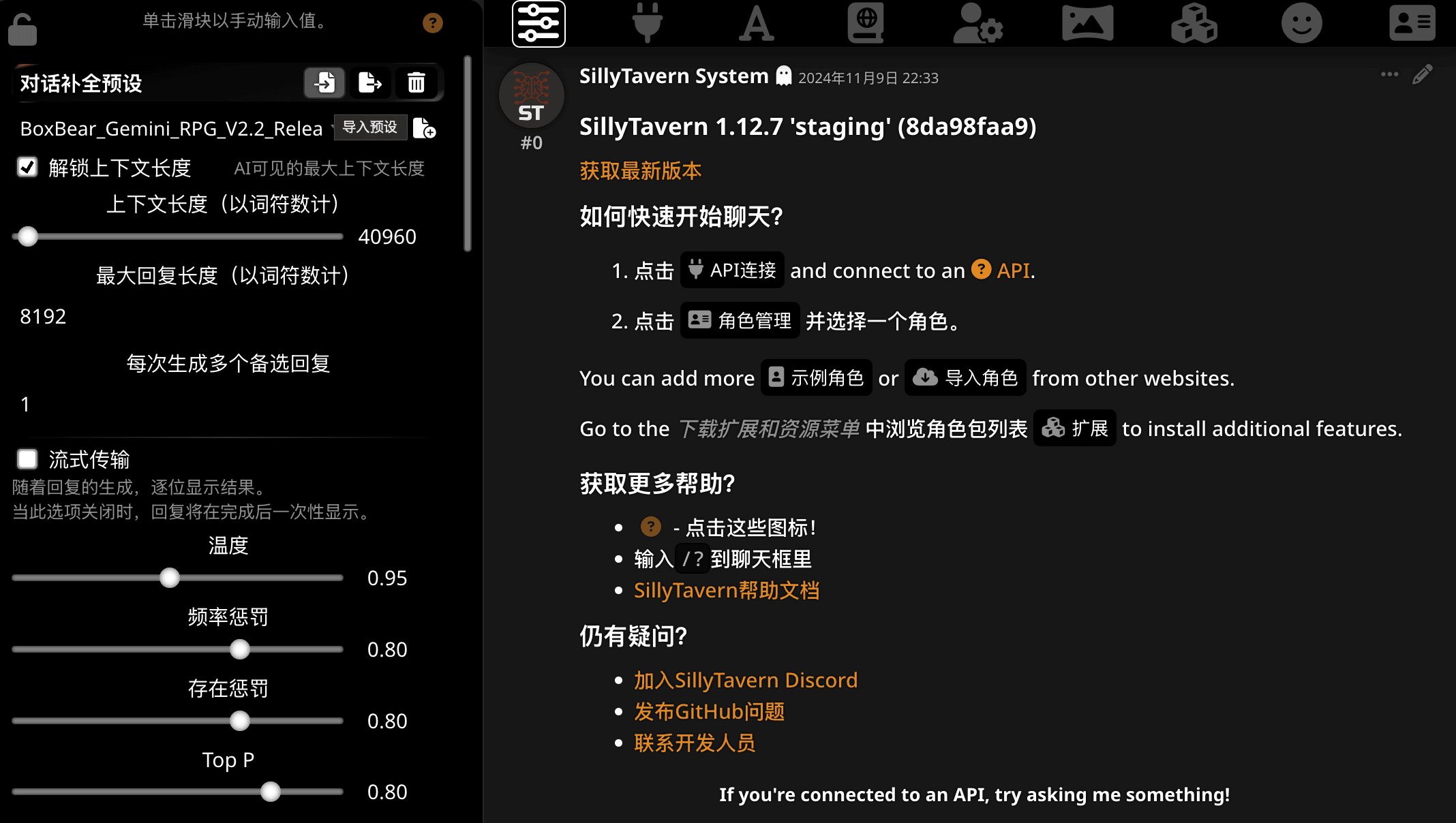
点击最左边的 “AI 响应配置”按钮打开对话补全预设菜单。找截图中用鼠标悬停着的按钮,就是导入按钮。
找不到导入按钮?
如果你因为各种原因还在使用 1.12.5 及以前版本,请回到安装一节的末尾,确保用户设置是”高级“模式。
调整预设共通设置
也就是选择预设下面的这些部分。
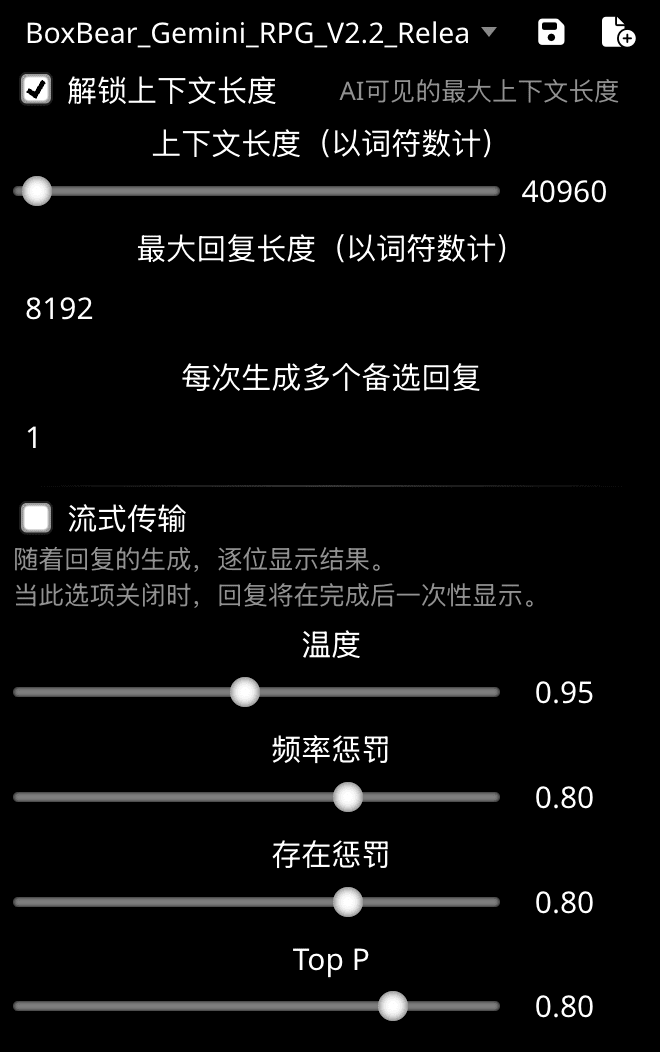
如果你使用的是 Claude 或者 Gemini 的话,你的设置选项也许会短一些。
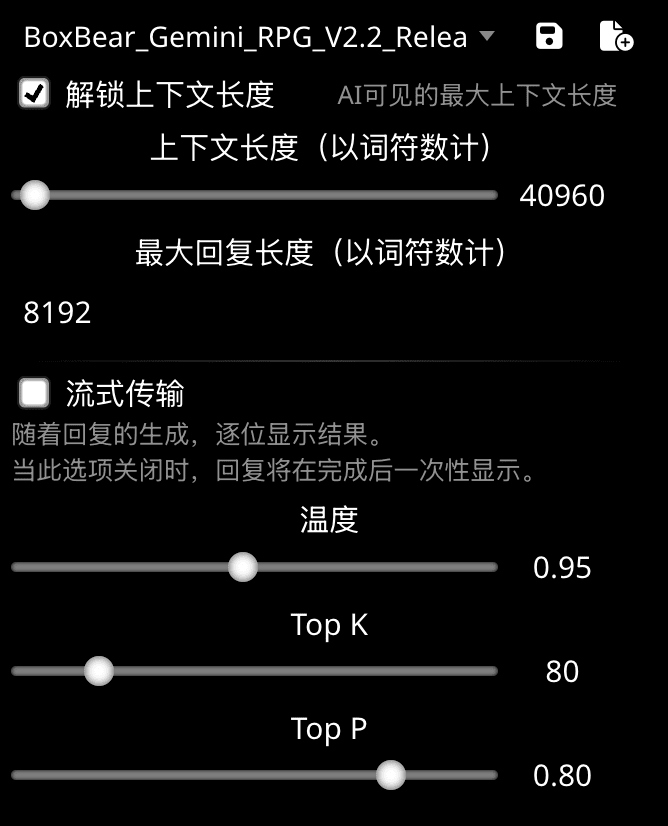
上下文长度,最大回复长度和流式传输模式
推荐勾选“解锁上下文长度”选项,这只是让你在酒馆的菜单中可调节的范围增大,并不会真正的提高每次发送 Tokens 的数量。
重要的是下面“上下文长度”的滑块。上下文长度越大,你每一轮对话中能够发送的世界书条目和历史记录就更多,当然花的钱也会变多。
至于最大回复长度,建议是设置成你的模型能够提供的输出上限(例如 Gemini 最长 8192 个 Token,Claude 最长 4096 个这样)。 或者,你也可以稍微降低一些来减少出现重复的机率。
流式传输模式下,AI 的回复会几个词几个词的显示,关闭可以减轻 Gemini 一类的模型在输出时发生截断的可能性。
那些滑块对应的参数
Important
假如你看不懂是什么意思,那么预设的默认值应该就足够了。
-
温度控制 token 选择的随机性。
-
当您期望得到真实或正确的回答时,温度越低越好。温度为 0 表示通常会选择概率最高的 token。 较高的温度可能会引发多样化或意想不到的结果。有些模型设置了更高的温度上限,以鼓励更为随机的回答。
-
大部分模型的温度范围是 0-2。
-
-
Top-K 和 Top-P 是两种不同的控制模型在选择输出 token 的方式。
- Top-K 指定模型在选择输出 token 时候选 token 的数量。使用较低的值可获得随机程度较低的回答,指定较高的值可获得随机程度较高的回答。
- Top-P 可更改模型选择输出 token 的方式。系统会按照概率从最高到最低的顺序选择 token,直到所选 token 的概率总和等于 Top-p 的值。例如,如果 token A、B 和 C 的概率分别是 0.3、0.2 和 0.1,并且 Top-p 的值为 0.5,则模型将选择 A 或 B 作为下一个 token(通过温度确定)。如需获得变化程度最低的结果,请将 top-P 设置为 0。
-
频率惩罚和存在惩罚是 OpenAI API 常用的控制模型输出重复程度的参数。
- 频率惩罚用于阻止模型在生成的文本中过于频繁地重复相同的单词或短语。每次在生成的文本中出现一个标记时,它都会被加到该标记的对数概率上。值越高,模型在使用重复标记时就越保守。
- 存在惩罚用于鼓励模型在生成的文本中包含各种标记。每次生成一个标记时,都会从该标记的对数概率中减去一个值。较高的存在惩罚值将导致模型更有可能生成尚未包含在生成文本中的标记。
开启或关闭预设条目
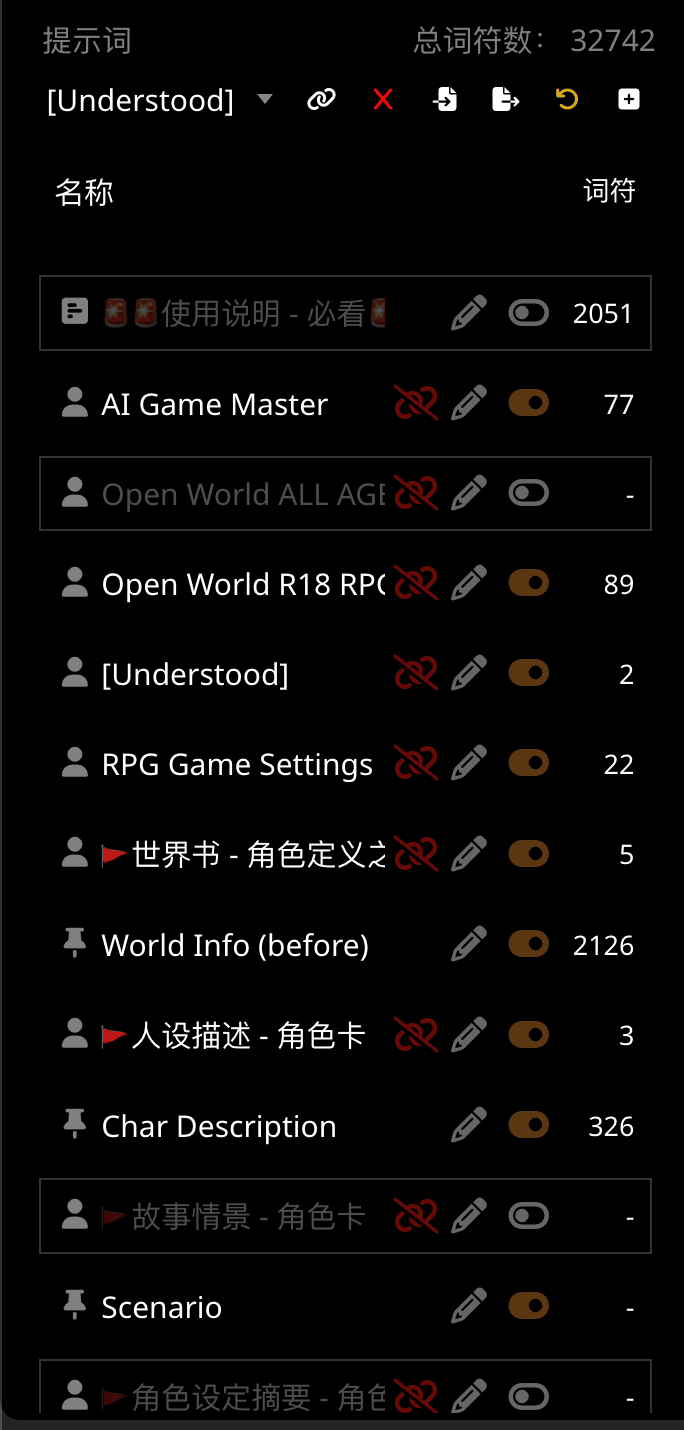
大多数的预设都会提供不同的可以选择开关的分段。对于每一个小节:
- 第一个红色的删除链接图标是将这段从要发送的内容中断开链接。 预设的第一分段,和酒馆内置的分段(世界信息、人物信息和聊天记录等)没有这种选项,通常你也没有必要用它。
-
第二个铅笔按钮可以查看和编辑这一分段中的内容,有些预设作者会把如何使用等信息填在第一个分段内,建议读完它。
-
第三个按钮就是开关,点击可在启用或禁用此分段间切换。
-
最后的数字表示这个分段占用的词符(Token)数量。
记得确认总词符数
预设分段最上面的“总词符数”表示当前预设所有项目会占用多少 Token ,请确保你上面设置的上下文上限比总词符数要大。